Giuseppe Lippi
Sezione di Biochimica Clinica, Università degli Studi di Verona, Verona, Italia
Tendenze Nuove n.2 – 2019; 19-24: DOI: 10.32032/TENDENZE201912.PDF
 Scarica Pdf
Scarica Pdf
Ancora oggi la diagnostica deve essere considerata una scienza sostanzialmente empirica, giacché il ragionamento clinico si basa sulla combinazione di anamnesi ed esame obiettivo e sui risultati di indagini diagnostiche, riecheggiando così la celeberrima osservazione di Sir William Osler, secondo cui “la medicina è la scienza dell’incertezza e l’arte della probabilità”(1). Secondo questa puntuale definizione, il ragionamento diagnostico verte in larga misura su capacità umane, congenite o acquisibili dopo anni di istruzione e formazione(2). In linea con questa premessa, il ragionamento diagnostico è ampiamente perfettibile, cosicché mezzi innovativi ed efficaci che possano contribuire a migliorare le capacità umane e gestire più efficientemente l’elevata complessità biologica che caratterizza la maggior parte delle malattie dovrebbero essere accolti con grande entusiasmo.
Il concetto di “Machine Learning”, tradotto in italiano in termini di “apprendimento automatico” o “statistica computazionale”, rappresenta una branca importante dell’Intelligenza Artificiale (IA), convenzionalmente definita come scienza che usa tecniche statistiche per migliorare progressivamente le prestazioni di un algoritmo prede nito nell’identi care modelli nei dati(3). In parole povere, l’apprendimento automatico sfrutta algoritmi prede niti e tecniche statistiche, compresi quelli propri della medicina clinica, per analisi obiettiva di dati biomedici multimodali allo scopo – almeno per quanto concerne la diagnostica di laboratorio – di migliorare lo screening, la diagnosi, la valutazione prognostica e il monitoraggio terapeutico delle patologie(4).
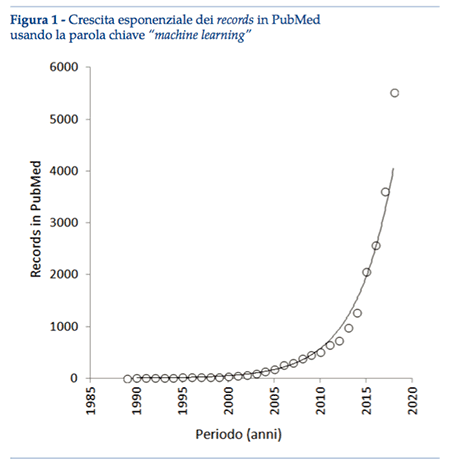
Una semplice ricerca elettronica in Medline (interfaccia PubMed) utilizzando la parola chiave “machine learning” produce 25.323 risultati al momento della pubblicazione di questo articolo, esibendo una curva temporale caratterizzata da un trend esponenziale quasi perfetto nel corso degli ultimi 30 anni (figura 1; r=0.989; p<0.001). Aggiungendo la parola chiave “medicina di laboratorio”, l’esito della ricerca è di circa 200 documenti, caratterizzato da un trend esponenziale ancora migliore nel corso degli ultimi 10 anni (r=0.994; p<0.001). Questo enorme interesse per l’apprendimento automatico, congiuntamente alle potenziali applicazioni in Medicina di Laboratorio, sta generando considerevole entusiasmo nella comunità scientifica(5-7). L’ipotesi che l’apprendimento automatico possa sostituire parzialmente o integralmente il cervello del medico è prospettiva intrigante, giacché i computer tendono ad essere praticamente infallibili se correttamente “istruiti”. A differenza dei computer, il cervello umano è vulnerabile agli errori, soprattutto quando si trova ad affrontare problemi complessi e variegati, come l’integrazione di molte informazioni demografiche, cliniche, ambientali e strumentali, al fine di formulare una diagnosi. Benché il recente entusiasmo nelle potenziali applicazioni offerte dall’apprendimento automatico sia sostanzialmente comprensibile, non potendo negarsi il valido contributo che l’IA può portare al processo decisionale clinico(5-7), molte altre ragioni fanno altresì supporre che il suo attuale valore nell’ambito della diagnostica di laboratorio sia forse sovrastimato.
La prima, e probabilmente più ragionevole, fonte di preoccupazione è che l’apprendimento automatico è ancora molto dipendente dalla controparte umana. Ciò è legato al fatto che gli “umani” decidono quale sia la condizione patologica che deve essere analizzata, gli “umani” identificano quale sia la popolazione e il disegno dello studio (trasversale, retrospettivo, prospettico o altro), gli “umani” decidono quali siano le variabili demografiche, cliniche o diagnostiche da inserire nel sistema, gli “umani” delineano quali test statistici debbano essere utilizzati, gli “umani” interpretano i risultati dell’analisi statistica e definiscono se questi siano clinicamente validi, gli “umani” assegnano un budget di errore ai modelli predittivi e, ultimo ma non meno importante, gli “umani” determinano “se”, “dove”, “quando” e “come” il modello possa essere introdotto nella pratica clinica. Indipendentemente da questi aspetti, dovrà poi essere definito convincentemente chi sia il responsabile della validazione del modello prima dell’introduzione nella pratica clinica. Questo importante aspetto nel processo di traslazione dalla ricerca di base alla clinica (“from bench to bedside”) non può essere ovviamente demandato alle software house o ai singoli ricercatori, ma necessita di un attivo coinvolgimento delle società scientifiche.
Un secondo e altrettanto importante aspetto è che i computer, anche quelli meglio istruiti, non saranno mai in grado di usare la “Gestalt”, intesa come percezione (parzialmente innata e parzialmente formabile) che consente al clinico di integrare diversi elementi diagnostici, più o meno consapevolmente(8). Anche la macchina più complessa esegue comandi umani, segue rigidi schemi di ragionamento (diagnostico) più velocemente degli umani, ma non sarà mai in grado di estendere l’analisi oltre gli elementi essenziali che gli umani hanno per lei definito e incorporato. Almeno non nel futuro prossimo.
Come può quindi integrarsi l’apprendimento automatico con la Medicina (di Laboratorio) personalizzata? La Medicina (di Laboratorio) di precisione può essere de nita come un processo finalizzato a formulare la diagnosi giusta, per il paziente giusto, al momento giusto(9). La progressiva transizione da test fenotipici convenzionali all’ampio uso di strategie diagnostiche innovative, basate sul rilevamento di anomalie genetiche e/o epigenetiche, difficilmente s’integra con l’inadeguata plasticità dell’apprendimento automatico. La gestione clinica di alcune malattie – i tumori sono un esempio paradigmatico – si basa sempre di più sull’identificazione di mutazioni somatiche altamente specifiche che influenzano il decorso clinico, nonché l’uso di terapie mirate e personalizzate, funzionali a rispondere ad un determinato genotipo. Queste tecnologie dirompenti stanno portando all’obsolescenza molti algoritmi diagnostici e terapeutici, rendendo quindi virtualmente super ua la loro possibile integrazione con l’apprendimento automatico(10).
Il potenziale svilimento del legame tra laboratorio e clinica, che è alla base dell’utilizzo efficace ed efficiente delle risorse di laboratorio, è un altro importante svantaggio legato alla diffusione dell’apprendimento automatico. La maggior parte dei professionisti di laboratorio è attivamente coinvolta nella promozione dell’uso appropriato ed efficace delle risorse di laboratorio(1). Come sarà possibile mantenere questa “liaison” virtuosa tra clinica e laboratorio se la progressiva diffusione dell’apprendimento automatico toglierà centralità ai professionisti di Medicina di Laboratorio nell’ambito del processo diagnostico?
Un’ultima osservazione riguarda la responsabilità oggettiva per difetti o errori dell’apprendimento automatico. Chi ne sarà responsabile? Chi ha sviluppato gli algoritmi? La software house? L’organizzazione sanitaria? Il singolo medico? Gli algoritmi danno spesso l’illusione di essere infallibili, ma sono stati sviluppati da uomini che hanno utilizzato uno specifico complesso d’informazioni che non replica necessariamente le molteplici e variegate circostanze locali (ad esempio, le popolazioni sono eterogenee per caratteristiche quali sesso, età, origine etnica, background genetico, co- morbidità, esposizione ambientale). Superfluo è anche sottolineare che la stragrande maggioranza degli errori umani sono cognitivi in sostanza, mentre un errore informatico è tipicamente ripetitivo, poiché ad oggi non può essere corretto senza un intervento (umano) esterno. La recente vicenda che ha coinvolto i Boeing 737 Max 8, per cui – dopo alcuni gravi incidenti – si è rilevato un problema di software, ne è purtroppo una limpida, oltreché inquietante dimostrazione.
In conclusione, riesce alquanto difficile stabilire se l’apprendimento automatico diverrà una preziosa risorsa per la medicina di laboratorio o si rivelerà piuttosto una grande bufala. Nessuna delle due ipotesi è forse completamente corretta o completamente errata. Ciò che è oggettivamente chiaro, è che i molti svantaggi attuali dell’apprendimento automatico, riassunti in tabella 1, non ne faranno una panacea, né è ragionevole supporre che l’IA sostituirà a breve il ragionamento umano durante tutto il processo diagnostico. Nel romanzo più celebre sull’IA e sulla robotica, il famoso scrittore e scienziato Isaac Asimov (fu Professore di Biochimica presso l’Università di Boston) ha concepito le tre famose leggi della robotica; la seconda di queste leggi afferma che “un robot deve obbedire agli ordini impartiti dall’uomo (tranne quando tali ordini entrano in conflitto con la Prima Legge della Robotica)” (Isaac Asimov. I, Robot. 1950). In questa semplice e lapalissiana premessa, il ricorso al concetto “deve obbedire … agli umani” è illuminante, e definisce un ambito preciso in cui l’IA è (e si spera rimarrà) subordinata all’intelligenza umana.

Pertanto, se alla fine di questo controverso articolo si rende necessario trarre delle conclusioni, appare evidente che l’apprendimento automatico sia ormai ben più di una semplice prospettiva per la medicina moderna, come recentemente sottolineato da Bergl et al(11), poiché esso è già in grado di fornire un valido supporto al ragionamento diagnostico. Nondimeno, è auspicabile che la sua assistenza si limiti ad un supporto di consulenza, operando sempre sotto la supervisione dell’uomo e mai surrogando completamente il cervello umano. Qualora dovessi ammalarmi, mi guarderei bene dall’affidarmi completamente ad un software – per quanto elaborato e preciso – per farmi diagnosticare e/o curare. E ho pochi dubbi che la stragrande maggioranza dei nostri pazienti la stia pensando allo stesso modo.
Bibliografia
- Plebani M, et al. A manifesto for the future of laboratory medicine professionals. Clin Chim Acta 2019; 489: 49-52.
- Lippi G, Cervellin G. From laboratory instrumentation to physician’s brain calibration: the next frontier for improving diagnostic accuracy?J Lab Precis Med 2017; 2: 74.
- Panch T, et al. Arti cial intelligence, machine learning and health systems.J Glob Health 2018; 8: 020303.
- Sajda P. Machine learning for detection and diagnosis of disease.Ann Rev Biomed Eng 2006; 8: 537-65.
- Gopal G, et al. Digital transformation in healthcare – architectures of present and future information technologies. Clin Chem Lab Med 2019; 57: 328-35.
- Cabitza F, Ban G. Machine learning in laboratory medicine: waiting for the ood? Clin Chem Lab Med 2018; 56: 516-24.
- Gruson D, et al. Data science, arti cial intelligence, and machine learning: Opportunities for laboratory medicine and the value of positive regulation.Clin Biochem 2019; 69: 1-7.
- Cervellin G, et al. Do clinicians decide relying primarily on Bayesians principles or on Gestalt perception? Some pearls and pitfalls of Gestalt perception in medicine. Intern Emerg Med 2014; 9: 513-9.
- Plebani M. Towards a new paradigm in laboratory medicine: the ve rights.Clin Chem Lab Med 2016; 54: 1881-91.
- Lippi G, et al. The future of laboratory medicine in the era of precision medicine. J Lab Precis Med 2016; 1: 7.
- Bergl PA, et al. Controversies in diagnosis: contemporary debates
in the diagnostic safety literature. Diagnosis (Berl) 2019. doi: 10.1515/ dx-2019-0016. [Epub ahead of print].



